

V - HOE KUNNEN RESULTATEN GEVALIDEERD WORDEN
2- ACCURAATHEID VAN DE GEGEVENS
Naast de geografische positie moet ook de inhoud van de gegevens juist zijn. Tenminste, ze moet zo nauwkeurig mogelijk zijn want 100% correcte gegevens bestaan enkel in een ideale wereld. Gebruikers van de data moeten in elk geval een idee hebben van het type fouten dat er inzit en van hun grootteorde.
In het geval van thematische kaarten die afgeleid werden uit beeldclassificaties willen we weten of de bodemgebruiksklassen die we op de kaart zien (bvb. bos, wegen, bebouwing…) wel degelijk overeenstemmen met de werkelijkheid en willen we een idee hebben van welke klassen eventueel met mekaar verward zijn.
In het geval van kwantitatieve teledetectiegegegevens (oppervlaktevariabelen zoals bvb. primaire productie of oppervlaktetemperaratuur) willen we een idee hebben van de grootteorde van de fout en van de standaardafwijking.
Om teledetectiegegevens te valideren wordt gebruik gemaakt van referentiegegevens, soms ook wel ground truth genoemd. Die kunnen we verkrijgen uit verschillende bronnen (interpretatie van luchtfoto's, thematische kaarten, grondmetingen,...) en ze kunnen voorkomen in verschillende vormen (digitale kaarten, sensormetingen, grafieken,...). Dergelijke referentiegegevens bieden niet enkel aanvullende informatie bij de analyse van teledetectiegegevens, ze maken het dus ook mogelijk om te controleren of deze correct worden geïnterpreteerd.





Voorbeeld 1: bepalen van fouten in thematische kaarten bekomen door beeldclassificatie
Om fouten te kwantificeren in thematische kaarten die afgeleid werden uit satellietbeelden kunnen we gebruik maken van een zogenaamde confusiematrix. Voor een aantal controlepunten (voorbeelden aangeduid op het beeld rechts) bepalen we de klasse waartoe de overeenstemmende beeldpixels werkelijk behoren. Deze zogenaamde ground truth bekomen we door visuele interpretatie en/of controle ter plaatse met een GPS (GNSS toestel). Door elk controlepunt in een matrix te plaatsen waarbij de werkelijke klassen in de kolommen staan en de toegewezen klassen in de rijen kunnen we een aantal foutenstatistieken berekenen. Zo bekomen we bijvoorbeeld het percentage juist geclassificeerde pixels door de som van de waarden op de diagonaal (blauwe ellips) te delen door het totale aantal controlepunten. In het fictieve voorbeeld hiernaast is dat 328 : 499 of ongeveer 66%.
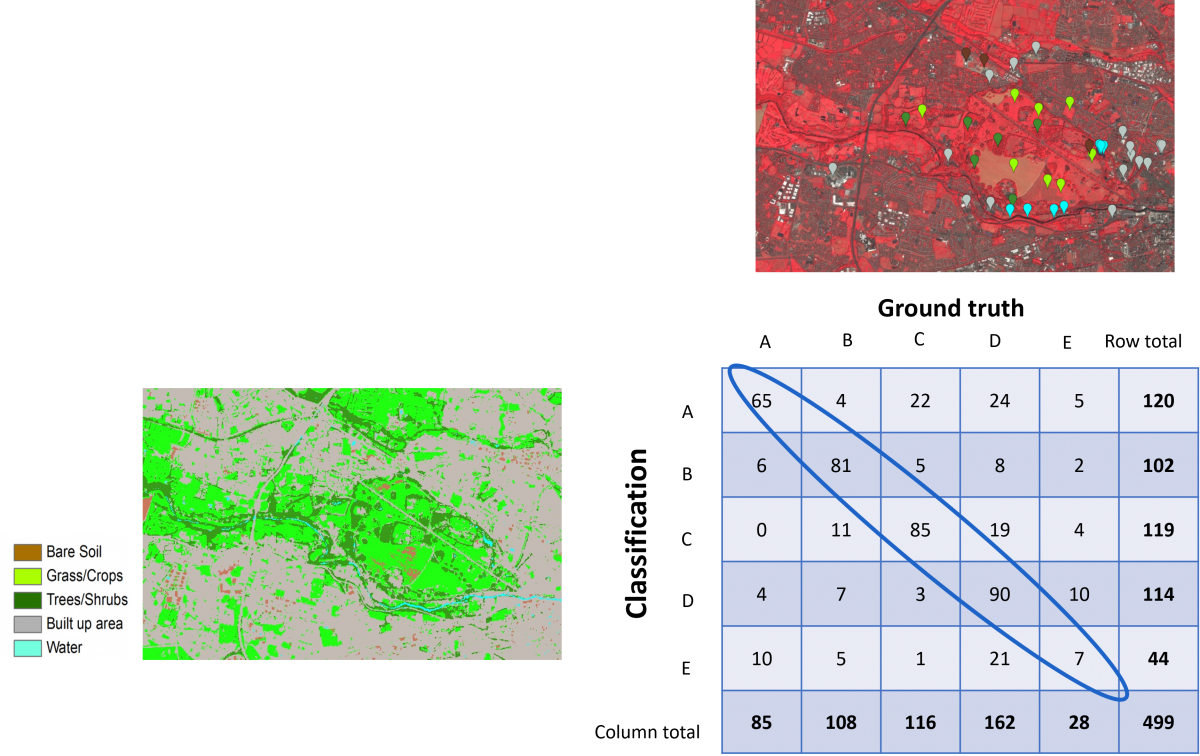
Eenvoudige bodembedekkingskaart van een deel van Dublin (omgeving Phoenix Park, linksonder) afgeleid uit een Sentinel 2 beeld dat werd opgenomen op 13 augustus 2022 (rechtsboven). Het gebruikte classificatiealgoritme is Random Forest (een zogenaamd machine learning algoritme). Er zijn duidelijke fouten aanwezig op de kaart. Zo zijn sommige gebouwen die behoren tot een industrieterrein foutief toegewezen aan de klasse “naakte bodem”. Omgekeerd zijn enkele braakliggende landbouwpercelen geclassificeerd als “bebouwd gebied”. De confusiematrix (fictief voorbeeld rechtsonder) maakt het mogelijk om de verwarring tussen de verschillende klassen te bestuderen en om een aantal foutenmaten te berekenen. Dit zowel op niveau van de hele kaart (bvb. totaal aantal juist of fout geklassificeerde pixels) als op het niveau van individuele klassen (bvb. “hoeveel van de pixels gras op de kaart zijn werkelijk gras?” of “hoeveel van de werkelijke pixels “gras” in onze ground truth werden juist toegewezen?”.
Voorbeeld 2 : bepalen van fouten in kwantitatieve teledetectiegegevens
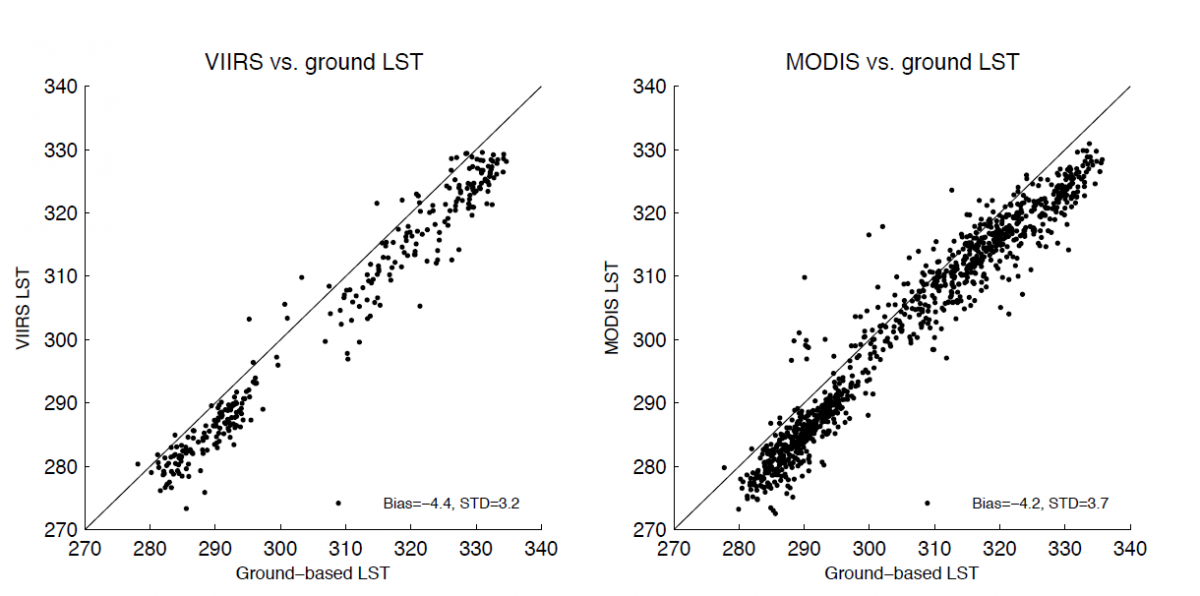
Vergelijking van VIIRS (links) en MODIS (rechts) teledetectieproducten die de temperatuur van het landoppervlak weergeven (eng.: land surface temperature – LST) versus de landoppervlaktetemperatuur die daadwerkelijk gemeten werd door weerstations in Gobabeb, Namibië. Vanwege een verkeerde schatting van de oppervlakte-emissiviteitswaarden die in de algoritmen worden gebruikt, onderschatten zowel VIIRS- als MODIS-producten de LST van de Namibische woestijn met gemiddeld meer dan 4 graden Kelvin. De figuur illustreert de noodzaak aan grondreferentie gegegevens: twee verschillende teledetectie-LST-producten kunnen onderling zeer goed overeenkomen omdat een vergelijkbaar algoritme gebruikt werd, maar ze kunnen aanzienlijk verschillen van de overeenkomstige referentiemetingen op de grond. Bron: Guillevic, P.C. et al. (2014). Validation of Land Surface Temperature products derived from the Visible Infrared Imaging Radiometer Suite (VIIRS) using ground-based and heritage satellite measurements, Remote Sensing of Environment, 154, p. 19-37, ISSN 0034-4257