

IV - VAN DATA TOT INFORMATIE
4- HOE KUNNEN WE BEELDEN ANALYSEREN EN KAARTEN PRODUCEREN?
4.4- Hoe beelden/data classificeren?
Objecten van vergelijkbare aard hebben meestal ook gelijkaardige beeldkenmerken. Denk bijvoorbeeld aan vegetatie die sterk reflecteert in het infrarode spectrum, aan woonhuizen die meestal duidelijk andere vormkenmerken hebben dan fabrieksgebouwen of aan landbouwpercelen die andere textuurkenmerken vertonen dan bossen.
Beeldkenmerken worden al geruime tijd gebruikt voor visuele interpretatie van luchtfoto's en satellietbeelden. De beeldanalist groepeert dan objecten in het beeld die gelijkaardige kenmerken vertonen (zie Hoe kan een beeld visueel geanalyseerd worden?). Zo wordt het beeld ingedeeld in verschillende deelgebieden die elk toegewezen worden een bepaalde categorie. Elke beeldpixel wordt als het ware “geklassificeerd”, dwz. toegewezen aan een bepaalde klasse.
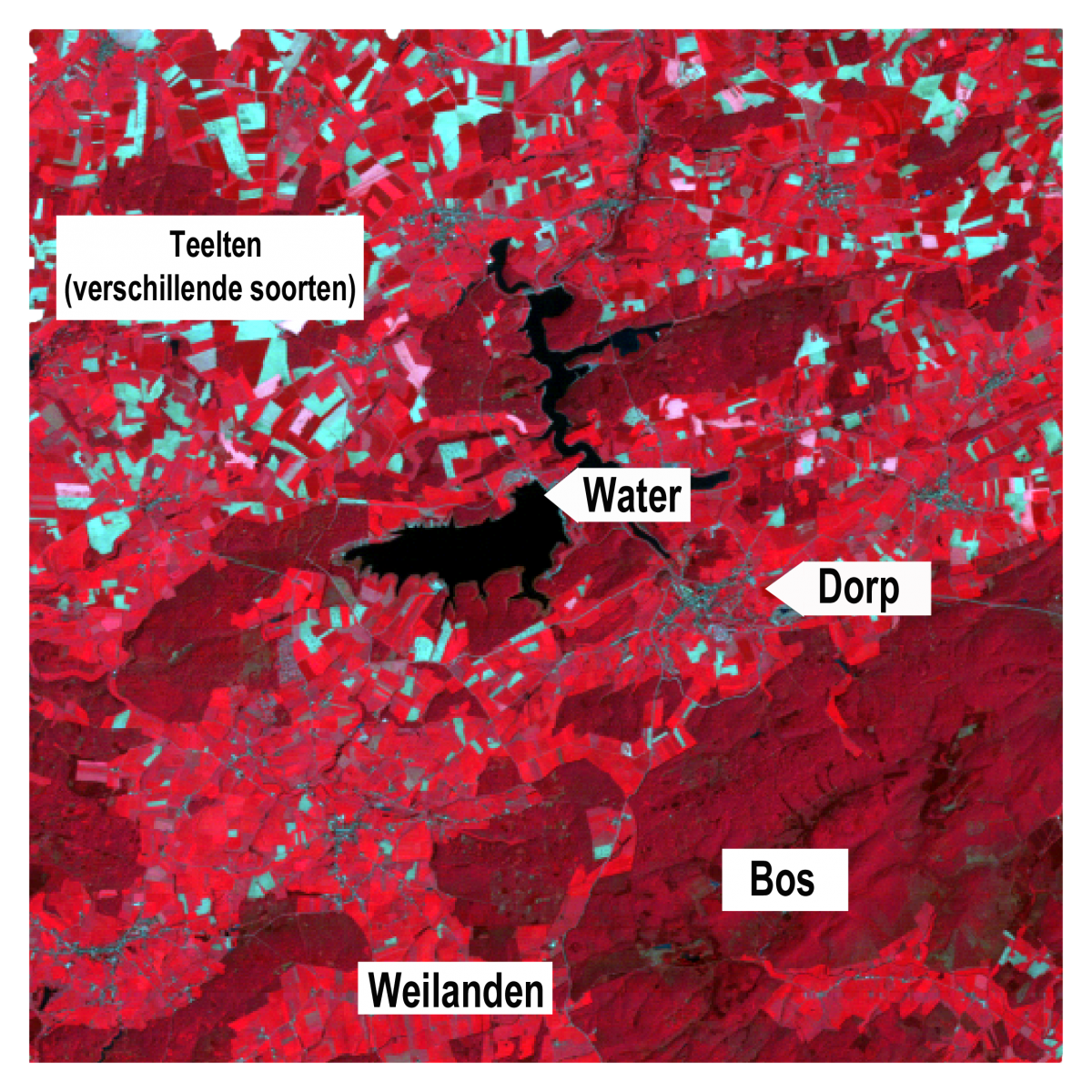
Bovenstaande figuur toont een deel van een satellietbeeld dat in de lente door de Thematic Mapper sensor van de Landsat 4 satelliet werd opgenomen. Het getoonde gebied is de regio rond het stuwmeer van de Platte-Taille en de meren van L’Eau d’Heure in de buurt van Philippeville. Het beeld wordt weergegeven als een valse kleurencomposiet waarbij het infrarode, het rode en het groene spectrale kanaal respectievelijk toegewezen worden aan de rode, groene en blauwe beeldschermkleur. Op basis van verschillen in kleur, intensiteit, vormen en texturen kunnen we visueel een aantal klassen onderscheiden. Zo zijn de meren van Eau d'Heure heel donkerblauw (bijna zwart), zijn de wegen en bewoonde gebieden vrij donker grijsblauw, zijn de loofbossen, die dominant zijn in de regio donkerrood en lijken de weinige plekken met naaldbomen donkerder bruin.
Aangezien digitale beelden niets anders zijn dan matrices met getallen kunnen we de rekenkracht van computers inzetten om ze te analyseren en te interpreteren.
De eerste computeralgoritmes die ontwikkeld werden om beeldclassificaties te maken baseerden zich uitsluitend op spectrale kenmerken van individuele pixels. De beeldsensor aan boord van vliegtuigen of satellieten registreert immers de zogenaamde spectrale signatuur van de objecten op het aardoppervlak. Objecten van gelijke aard hebben meestal gelijke spectrale eigenschappen. Dit betekent dat de elektromagnetische straling die door objecten van hetzelfde type wordt weerkaatst, in grote lijnen vergelijkbaar is en dat deze objecten daarom nauwe spectrale signaturen zullen hebben.
We kunnen twee grote groepen van pixelgebaseerde classificatiealgoritmes onderscheiden. Een eerste soort, de zogenaamd “gesuperviseerde” classificatie, zal de spectrale waarden van een pixel vergelijken met “referentiesignaturen” van een aantal vooraf gedefinieerde klassen en de pixel toewijzen aan de klasse waarmee de spectrale kenmerken het best overeenkomen. Om dergelijk algoritme te kunnen toepassen moeten we dus op voorhand bepalen welke spectrale klassen we willen onderscheiden en weten wat hun spectrale kenmerken zijn.
Een andere benadering is het zogenaamd “niet-gesuperviseerde” algoritme. Dat werkt niet met vooraf bepaalde klassen maar voert een automatische groepering of “clustering” uit van de spectrale waarden van pixels. Pixels met gelijkaardige waarden worden dan in eenzelfde groep ondergebracht. Het is dan aan de gebruiker om deze groepen na de classificatie te interpreteren en in verband te brengen met de bodembedekking.
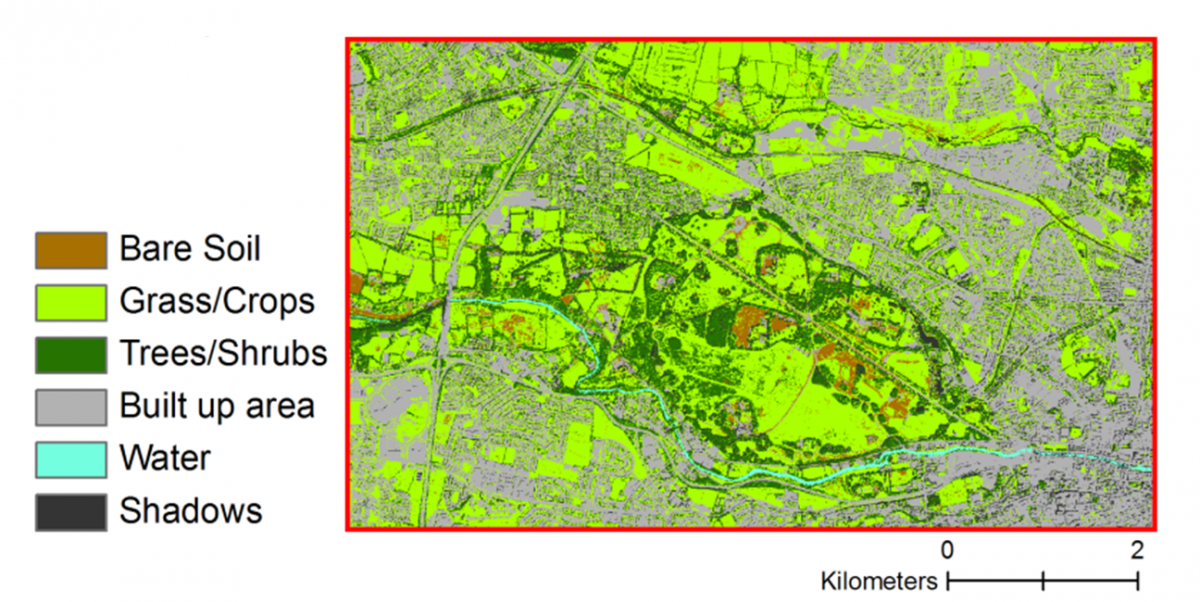
Bovenstaande figuur toont de classificatie van een hoog-resolutie satellietbeeld van een Deel van Dublin (Phoenix Park). Het algoritme dat gebruikt werd voor de classificatie deelt individuele pixels in vooraf gedefinieerde klassen in op basis van enkel spectrale kenmerken.
Hoewel spectrale signaturen ons al veel kunnen vertellen over de aard van de objecten hebben classificatie-algoritmen die enkel naar de spectrale waarden van individuele pixels kijken een hoop nadelen. Satellieten nemen vanuit hun baan immers enkel het bovenste deel waar van de buitenste schil van objecten. De satelliet "ziet" bijvoorbeeld alleen het dak van een huis.
Bovendien worden de spectrale eigenschappen van elke pixel afzonderlijk bekeken zonder rekening te houden met de vorm van de objecten of met wat er zich in de omgeving van de pixel afspeelt. In het beste geval kunnen we dan met dergelijke methoden gebouwen indelen enkel op basis van de spectrale kenmerken van de dakbedekkingsmaterialen terwijl vele gebruikers eerder geïnteresseerd zijn in een indeling op basis van de functie van het gebouw (residentieel, commercieel, industrieel, enz.). Deze beperking is vooral nadelig om kunstmatige elementen van het landschap te identificeren. De analyse van de spectrale signaturen van objecten is veel relevanter als het gaat om het analyseren van bodems, gewassen, natuurlijke vegetatie, enz.
Het is belangrijk om met dit basisprincipe rekening te houden bij het definiëren van de categorieën van een classificatie op basis van alleen maar spectrale kenmerken. Deze categorieën moeten immers altijd gebaseerd zijn op bodembedekkingstypes (eng.: land cover) in plaats van op patronen van landgebruik (eng.: land use). Een parkeerplaats en het asfalten dak van een gebouw vormen verschillende landgebruikspatronen, maar ze hebben spectrale signaturen die zo dichtbij mekaar liggen dat ze waarschijnlijk in dezelfde categorie zullen worden ingedeeld.
De meer recente classificatie-algoritmen maken gebruik van een veel ruimer arsenaal aan beeldkenmerken dan enkel de spectrale waarden van individuele pixels. Door de opkomst van machinaal leren (eng.: machine learning) en artificiële intelligentie is het mogelijk geworden om veel meer informatie uit een digitaal beeld te halen. Zo kunnen convolutionele neurale netwerken dankzij vormkenmerken die ze zelf aanleren uit een groot aantal voorbeelden bepaalde objecten in een landschap zoals gebouwen of archeologische overblijfselen identificeren, zelfs als deze objecten geen eenduidige spectrale eigenschappen hebben. Dergelijke algoritmen zijn ook in staat een beeld te segmenteren of in te delen in gebieden van pixels die behoren tot dezelfde categorie (bvb. straten, huizen, bomen, …).

Dankzij geavanceerde computeralgoritmen kunnen we de eeuwenoude steenheuvels die verspreid liggen in het uitgestrekte Altaï gebied (Rusland) vanuit de ruimte detecteren op hoge resolutie satellietbeelden (hier Gaofen-2). Deze algoritmen maken gebruik van artificiële intelligentie (zogenaamde “convolutional neural networks”) om de typische cirkelvormen van deze archeologische overblijfselen in het beeld te herkennen. Bron: Fen Chen et al, Automatic detection of burial mounds (kurgans) in the Altai Mountains. ISPRS Journal of Photogrammetry and Remote Sensing, Volume 177,2021, p. 217-237, ISSN 0924-2716.